1. NMS算法(非极大值抑制算法)
该算法主要目的是筛选出重复框,保留有效框。
主要用在 region proposal阶段以及最后框出的阶段。
假设进行非极大值抑制的输入为2000x20的矩阵,2000表示该图像上框的个数,20表示类别数:
具体步骤如下:
1 对2000×20维矩阵中每列按从大到小进行排序(每列表示一类,共20类。同一类可能有多个目标,如上图有两个人);
2 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IoU计算,若IoU>阈值,则剔除得分较小的建议框,否则认为图像中同一类物体有多个目标;两个同类的目标的建议框基本不会有重叠(因为两个同类在一张图片中肯定不会有大面积重叠啊),因此去掉建议框重叠较大的实际上是实现了剔除同一个目标的重叠框
3 从每列次大的得分建议框开始,重复步骤2;
4 重复步骤3直到遍历完该列所有建议框;
5 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
2. Batch Normalization reference
- 为什么要进行特征归一化:
- 归一化后加快了梯度下降求最优解的速度;
- 归一化有可能提高精度;
- 简单缩放 min-max
- 标准差标准化 z-score 0均值标准化(zero-mean normalization)
- 经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为
- 非线性归一化 比如log
- add in 2019-03-18
- 提出背景
- 网络更新参数后使得输出的分布发生变化(即下一层的输入的分布发生变化)。网络参数需要不断调整来适应这种变化 因此会影响网络的学习速率。其次 还会使网络输出进入饱和区,减缓网络的收敛速度。此成为Internal Convarite shift。
- 为解决这个问题 提出了归一化。即对每一个特征进行归一化,使其分布0均值 方差为1。
- 具体解决方案:
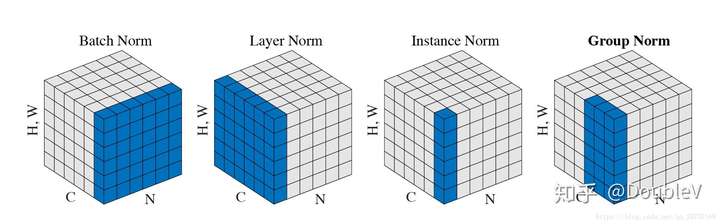
- BN。批归一化。即在每一个Batch的同一维度特征进行BN.
- LN。层归一化。避开Batch维度 在每一个输入上进行归一化 H*W*C上的归一化。
- IN。实例归一化。具体到某一次输入的每个channel上分别归一化。
- GN。介于LN 和 IN 的之间 将channel进行分组 然后进行归一化操作。
3.动量更新方法
传统SGD更新方法。更新速度慢
{.line-numbers} 1
x += -learning_rate * dx
momentum update
{.line-numbers} 1
2v += mu * v - learning_rate * dx
x += v
其中一般的,v初始为0,mu是优化参数,一般初始化参数为0.9,当使用交叉验证的时候,参数mu一般设置成[0.5,0.9,0.95,0.99],在开始训练的时候,梯度下降较快,可以设置mu为0.5,在一段时间后逐渐变慢了,mu可以设置为0.9、0.99。也正是因为有了“惯性”,这个比SGD会稳定一些。
4.CE交叉熵 与 BCE二分类交叉熵
二者是不一样的。参见(CE and BCE)[https://zhuanlan.zhihu.com/p/48078990]
5.BP算法
BP算法的整体思路如下:对于每个给定的训练样本,首先进行前向计算,计算出网络中每一层的激活值和网络的输出。对于最后一层(输出层),我们可以直接计算出网络的输出值与已经给出的标签值(label)直接的差距,我们将这个值定义为残差δ。对于输出层之前的隐藏层L,我们将根据L+1层各节点的加权平均值来计算第L层的残差。
插入一些我个人对BP算法的一点比较容易理解的解释(如有错误请指出):在反向传播 过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。不管下面的公式推导,还是后面的卷积神经网络,在反向传播的过程中,都是遵循这样的一个规律。
6.anchor的还原。
Q:在SSD YOLO 以及Faster-RCNN中均提出了一个anchor的概念,所以问题产生了:在feature map上产生的anchor是在怎么还原到原图上的呢?
- Faster R-CNN
Faster RCNN中采用33卷积 padding为1,然后经过2\2的pooling。输出的尺寸刚好类似于将原始图片进行了resize。故将anchor直接还原。(等待少卿确认) - SSD 中采用了类似的结构??
7.关于卷积的一些看法
顺便吐槽一下CNN结构:我们在做网络结构分析或网络结构设计的时候,经常会有这样的感觉,输出的数想让它代表什么就代表什么,有时候甚至看起来很没有道理,但是最后这样的操作却能有效果,最重要的原因就在于卷积操作是没有实际的意义的,它只是很强的抽取能力,但是它并不知道会抽取出什么东西,所以如果我们设计合适的损失函数,就可以任意指定输出,哪怕这种指定看起来并没有道理。CNN本质上就是连接input与output之间的一个极其复杂的,表达能力很强的,并且很有潜力的函数,但是这个函数最终的能力能不能充分发挥出来,要取决于很多东西,损失函数,训练技巧,数据集等等。
ref
8.转置卷积。
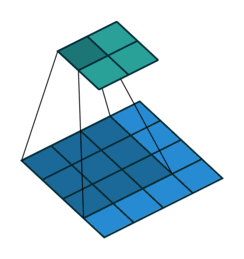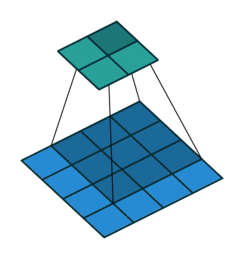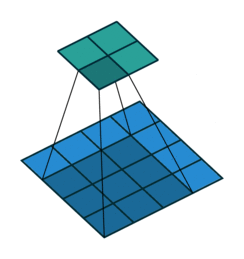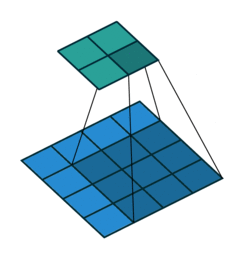
![]()
注意图中蓝色(下面)是输入,绿色(上面)是输出,卷积和反卷积在 p、s、k p、s、k 等参数一样时,是相当于 i i 和 o o 调了个位。
这里说明了反卷积的时候,是有补0的,即使人家管这叫no padding( p=0 p=0),这是因为卷积的时候从蓝色 4×4 4×4 缩小为绿色 2×2 2×2,所以对应的 p=0 p=0 反卷积应该从蓝色 2×2 2×2 扩展成绿色 4×4 4×4。而且转置并不是指这个 3×3 3×3 的核 w变为 w.T,但如果将卷积计算写成矩阵乘法(在程序中,为了提高卷积操作的效率,就可以这么干,比如tensorflow中就是这种实现), Y-> =CX-> (其中 Y->表示将Y→ 拉成一维向量, XX→ 同理),那么反卷积确实可以表示为 C.TY→,而这样的矩阵乘法,恰恰等于 W左右翻转再上下翻转后与补0的 Y 卷积的情况。
然后就产生了第三个confuse:“补0了会不会有影响,还能通过反卷积近似输入 X吗?”其实反卷积也不一定能达到近似的效果,图像里的卷积,相当于一种相关操作,而反卷积维持了这种相关操作时的 w与 X、与 Y 之间的联系维持了。至于补0后操作是否还等价,上一段已经说明了是等价的,读者可以在阅读完后面的文章后自己尝试一下。
tensorflow也是这样实现反卷积的。
9.对NN的核心贡献
- 目前来看,很多对 NN 的贡献(特别是核心的贡献),都在于NN的梯度流上,比如:
- sigmoid会饱和,造成梯度消失,于是有了ReLU。
- ReLU负半轴是死区,造成梯度变0,于是有了LeakyReLU,PReLU。
- 强调梯度和权值分布的稳定性,由此有了ELU,以及较新的SELU。
- 太深了,梯度传不下去,于是有了highway。
- 干脆连highway的参数都不要,直接变残差,于是有了ResNet。
- 强行稳定参数的均值和方差,于是有了BatchNorm。
- 在梯度流中增加噪声,于是有了 Dropout。
- RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。
- LSTM简化一下,有了GRU。
- GAN的JS散度有问题,会导致梯度消失或无效,于是有了WGAN。
- WGAN对梯度的clip有问题,于是有了WGAN-GP。